
 On December 2, 2021, the Longwood Medical Area Research Data Management Working Group hosted a bi-annual Data Management Showcase to inform the research community about its members, services, and resources. The session included an overview of the working group, resources for the community, and a panel discussion with various stakeholders. This blog post reports the presentations and discussions. A recording of the full webinar has been made available for viewing at the bottom of this webpage.
On December 2, 2021, the Longwood Medical Area Research Data Management Working Group hosted a bi-annual Data Management Showcase to inform the research community about its members, services, and resources. The session included an overview of the working group, resources for the community, and a panel discussion with various stakeholders. This blog post reports the presentations and discussions. A recording of the full webinar has been made available for viewing at the bottom of this webpage.
The Data Management Showcase started with an introduction by Julie Goldman, Research Data Services, Countway Library. Julie reviewed "what is research data management?" and the research data lifecycle, including the various activities, resources, and stakeholders involved at each stage of the process.
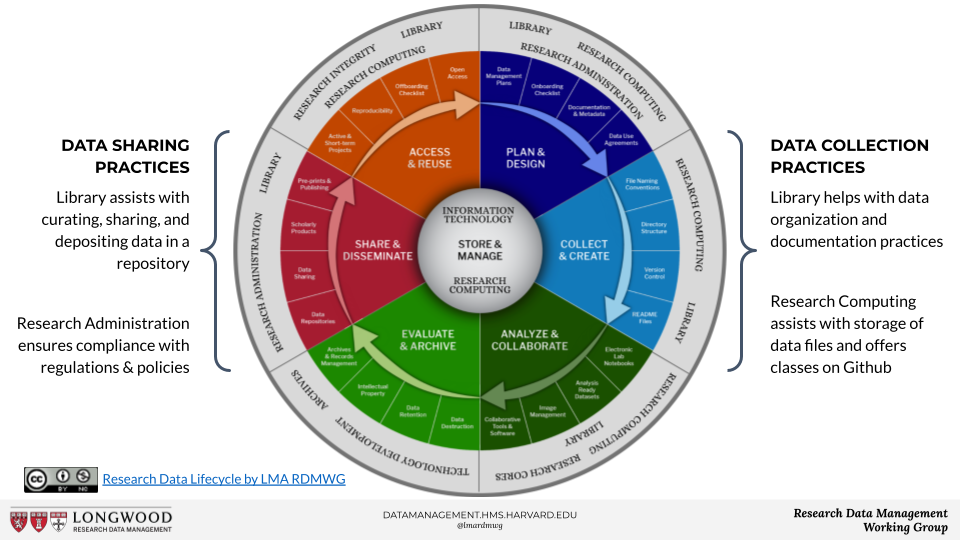
Next, Jessica Pierce, research data manager, HMS Research Computing, provided an overview of the LMA RDMWG. The working group is an amazing network of people and groups that are invested in data management practices and solving these problems. The group started in 2015 as the HMS Data Management Working Group, but it has grown to include members of the T.H. Chan School of Public Health and hospital affiliates. In order to reflect and include the members involved, the group was renamed the "Longwood Medical Area of Research Data Management Working Group." The group aims to build an inclusive community and focuses on real work to help the research community. The overall mission is to develop recommended practices, to meet current and anticipate future research data management needs of researchers across the LMA. The group has formed several subgroups to focus on distinct projects, mostly around resource development. The group found that in order to address challenges across disciplines and research communities, it's good to start broad and provide a straw-man for people to react to. The group identified broad research challenges, developed draft resources, and then solicited feedback from various stakeholders. In turn, these stakeholders can take a developed resource and apply it to their needs, and then see what works and what doesn't work.
The next section of the showcase featured working group members presenting the resources and services developed:
Sarah Hauserman, research data management analyst, HMS Research Computing, started by highlighting the Harvard Biomedical Research Data Management Website. The website really serves as a comprehensive repository of research data management resources. It offers guidance, best practices, all of which are designed to really assist researchers and groups across the Longwood Medical Area with the management of their research data throughout the data lifecycle. The website was designed to reflect each step of the data life cycle, allowing visitors to click on different segments of the lifecycle image to that specific topic. The group records most of the training sessions which allows participants to view the training materials on their own time. There are also relevant news articles, upcoming events, and a quarterly newsletter showcasing upcoming events and data management news. Check out the Harvard Biomedical Research Data Management Website.
Meghan Kerr, Longwood Medical Area Records Manager/Archivist, Center for the History of Medicine, shared the Research Data Lifecycle Checklist, which is a great resource for anyone just getting started with RDM! The checklist contains institutional policies that affect your data, who's going to be doing the different parts of the research data management plan, and what the different roles and responsibilities are. The checklist is broken into the six stages of the data lifecycle with the goal to help researchers stay on track throughout the project. It is important to be aware of what is expected at each stage of the data lifecycle, so prepare with the Research Data Lifecycle Checklist.
Julie Goldman, research data services librarian, Countway Library, shared another important aspect of data management: planning. A data management plan is a written document outlining plans for handling all of the data resulting from your research project in both the short term and the long term. Many funding agencies require a data management plan with your grant proposal. For example, the NIH recently released a new policy for data management and sharing, which will go into effect in January 2023, requiring these written data management plans with any grant proposal seeking research funds from the NIH. A very useful platform for creating a data management plan is called the DMPTool. DMPTool is a free platform that helps create data management plans that fulfill the requirements of different funders. The DMPTool supports templates from major funders who are requiring these plans. With the announcement of the forthcoming NIH policy, the working group developed templates for Harvard researchers to use. The templates keep the structure of a typical DMP, but include example texts, guiding prompts, and links to Harvard policies and resources. The templates were developed with standardized language, which reflects Harvard data management policies. The working group and library can help with creating a data management plan, the DMPTool website, or reviewing a draft data management plan. Find out more about Data Management Plans.
Caroline Shamu, associate dean for research cores and technology, HMS Office for Research Operations, next shared two key resources for managing data in the lab or in a project: the RDM Onboarding Checklist and RDM Offboarding Checklist. The RDM Onboarding Checklist helps individual researchers as they start in a new lab or start a new project to make sure that they're covering all the bases in terms of where they might put their data, and how they might communicate it that to their collaborators. It's really important early on, as you start in a lab or start a new project to understand, first of all, what the current lab practices are, and then if there's room for you to develop your own, or to work with other members of the lab, to initiate strategies for managing the lab or project's data. Then, equally important, is when you leave the lab or wind down a project. How you wrap up your data and leave it so that it can be accessed in the future and, importantly if you're leaving a lab so that your PI knows where the data are and your collaborators can continue to work on it. Therefore, the RDM Offboarding Checklist facilitates how knowledge is captured and transferred from a researcher to the lab or project group. This checklist helps determine what you need to store and then ways that you can make it accessible and share with your PI and other members of your lab. Get started with the RDM Onboarding Checklist and RDM Offboarding Checklist.
John Obrycki, research operations & BiOS Freezer Core manager, HSPH Department of Nutrition, introduced the Knowledge Transfer File as a part of the RDM Offboarding Checklist. The Knowledge Transfer File can be worked on at any point in a project. The Knowledge Transfer File is very similar to any README file from any project that you might be saving on some type of shared drive or other location. The goal of this file is to identify, prepare, and co-locate key research files for handoff and data sharing. You want to think about what projects and datasets that you want to capture because having all this information facilitates data sharing and reuse and it also increases the visibility of research. As people come and go on different projects, they graduate, they go off to the next great adventure, you don't want the new people coming in and getting frustrated because they can not find data or understand what someone worked on. With a Knowledge Transfer File, people can figure things out quickly and get started on the research, rather than getting frustrated and spending a lot of time trying to figure out what was done before they got to a group. Use the Knowledge Transfer File Template.
Allan Harris, manager, Research Computing Applications and Operations, HMS Research Computing, shared services and products for Electronic Lab Notebooks. An ELN or an electronic lab notebook is basically an extension of a physical notebook with a lot more capability. They provide the ability to store all the information about an experiment within a given project or study, including images, documents, sort of any type of other collaborative electronic data, you can kind of store all in one spot. Many of these products also have the ability to inventory, in quite extensive detail, the resources within the lab, including you know possible samples and things in your refrigerators, and other items that you might have in your lab for working. Within Harvard, there are two particular products being used: eLabJournal for Harvard Medical School and RSpace for Harvard University. Learn more about Electronic Lab Notebooks, including recommended practices and products across the LMA.
To close the session, Julie lead a panel discussion based on four main questions:
- What are your data management nightmare/horror stories?
- What are the major data management challenges you see with the researchers and students you support?
- What are the costs and consequences of the gaps in data management you see?
- What are one or two things you could do to help mitigate the above?
Dan Wainstock, director of research integrity, HMS Office for Academic and Research Integrity, kicked off the panel discussion with some of the consequences of both good and inadequate data management.
"...the nightmare or horror story that I have which, on the other hand, can be a real positive if if if your data management is is robust, isn't sometimes when these mistakes crop up in the research literature, you know, there's there's a whole group of people who are posting stuff to journal to websites like PubPeer saying "hey this can't be right?" "What's wrong?" "Is there something deeply wrong with this paper, or is this just a mistake?" And you know, and if data management isn't adequate to go back and find the data from that figure, from that published paper, then those questions can quickly escalate to like a full-scale inquiry or investigation, which, you know, can be really rough to deal with.
I mean that that is a real, that is a real nightmare, it was a real horror story. And just to say that when when when the data has been kept and managed in a way that's, you know, that's transparent, we could say FAIR, I don't know, I guess, we haven't talked about the fair principles. But, you know, findable, accessible, interoperable, and reusable. If it's all of those things, then when a question arises after the fact, it's really easy to go back and say "No look! All the data are here, and I grabbed the wrong thing and stuck in the figure. I'm sorry." And then the problem goes away because it's clear that it was just a simple [mistake]."
Meghan shared her work with lab notebooks.
"The major thing that I always, seems like my personal horror, is when I review lab notebooks and there's no last name, no year, it's just the person's first name and month and day and it's just basic metadata because-- sometimes these lab notebooks aren't even that old, but if I'm looking at lab notebooks from like 15 years ago, it's really hard to place when I'm trying to make a retention decision about what should happen, and it could be an amazing research, study, but if I can't-- the people who have left the lab can't-- there's no one there to answer the questions, there's no way to make sure the status were usable in the future. And I think that's what I see as like a big consequence in this just, yeah that lack of being able to reuse it."
John provided a real-life, in-the-movement data management snafu.
"...the example I have of a data management nightmare is more just one that I've done, which I hope to not repeat again, not from a lab notebook perspective, but just like when you're writing about a project, sort of the metadata related to a project, so like more the README file knowledge template file and that there was some important information and, of course, I was in a rush so I just had a notebook and I was writing in it, and to remember that this important information was there I put another extra piece on paper on the notebook so it stuck out, like a little bookmark. To be like "oh remember that's an important page!" I didn't write on the bookmark or anything and of course, didn't go back and try to capture that in a text document that would save somewhere on the shared drive or in a shared folder, or any kind of thing like that. And someone asked a question like "So what about this and this?" And I'm wondering like, you know, I have no idea, but I went back and pulled out this notebook and I was like "oh there's this important piece of paper sticking out that's totally unlabeled" and I flipped to that page and, oh that happened to be the page that the information was on. And that is the exact wrong way to do this, because of course it was unlabeled, it wasn't shared, it wasn't in any format that was transferable to other people. And it was one of those lucky events that I am not going to do again because it is a very poor data management practice."
Caroline provided some advice for faculty and PIs.
"I think, it'll be important for PIs really to address this explicitly and if we can encourage more PIs to do that, I think that that will help. Because the members of the lab are really looking for guidance from them on how to do it and, just as we carry out surveys and classes like this, and in other forums, we really find that you know, very few PIs actually directly address this with their students and postdocs."
Allan shared his perspective as an IT professional.
"...don't hoard your data! Don't think that you need to do it all by yourself. Come and find help, come and find, you know, come come to this group. Everything seems daunting at first, and you feel like you've got a roll your own, but the idea is that there are lots of tools, and there's lots of knowledge, and there are lots of ways to sort of bootstrap your studies and your data collection in a way that's going to be useful for not just yourself but for other people. Bring it to the collective and sort of start to embrace the data standards and your life will just be easier."
Sarah provided some crucial advice to researchers.
"I often say this in the trainings that we do, but it's it can sometimes feel overwhelming for people to see all the best practices that we offer. And they say "this is too much I can't do it all." And so I usually recommend that they start with something small and work their way up. So just something like changing file names to be more recognizable, adding a date, maybe a project name, maybe a version to a file name and suddenly you know you're more organized than you were before. Or starting to create a better structure for how you make your folders align, maybe start putting project data in a project folder, start putting data that belongs to a particular lab member in a folder with their name on it. So some of these really small simple things that you can do moving forward are going to have a big impact without a lot of time and effort. So I just recommend starting small and then seeing how far you can get. Because it can be overwhelming to say you know, I have to do a README file and a Knowledge Transfer File Template, and all this stuff, data management plan and, you know, just start off small and see what you can do and you'll be surprised by your future self, as Dan was saying, how you will be very excited later on what you've accomplished."
Watch the entire webinar recording to learn more about the working group, the resources, and more data management advice.

Watch the webinar recording!