
A key aspect of data sharing involves not only posting or publishing research articles on preprint servers or in scientific journals, but also making public the data, code, and materials that support the research. Data repositories are a centralized place to hold data, share data publicly, and organize data in a logical manner.
Benefits of Data Repositories
- manage your data
- organize and deposit your data
- cite your data by supplying a persistent identifier
- facilitate discovery of your data
- make your data more valuable for current and future research
- preserve your data for the long-run
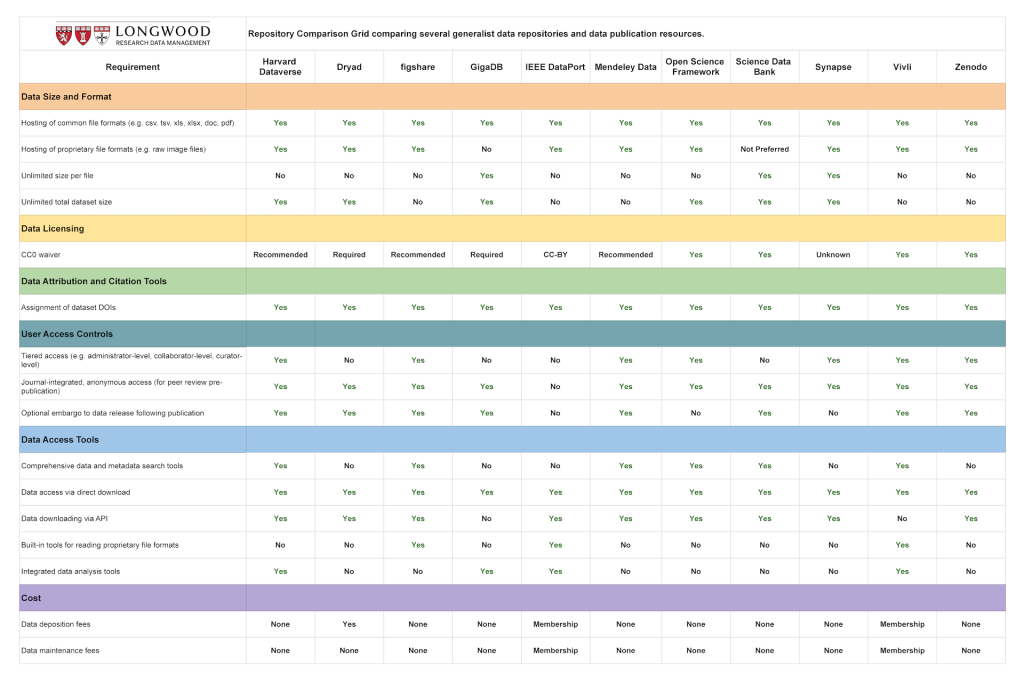
Repository Comparison Grid
The number of available resources for data sharing and data publication has increased substantially in recent years. You can search the re3data global registry of research data repositories to find appropriate academic discipline repositories.
We have also created a resource to compare and contrast several of the general data repositories currently available for NIH and biomedical science researchers. Detailed feature descriptions of each platform are available on the subpages of this page.
Click on the Harvard Biomedical Repository Matrix below to view an enlarged version of the table on Zenodo.
Accessible Repository Comparison
Repository Comparison List
Accessible text version of the information found in the Repository Comparison GridA PDF version of this information is also available on Zenodo.
Harvard Dataverse Features & Specifications
Data Size and Format
Hosting of common file formats (e.g. CSV, TSV, XLS, XLSX, DOC, PDF)
- Yes
- All file formats accepted (tabular, non-tabular, and compressed as a zip file bundle with file hierarchy feature to preserve directory structure).
Hosting of proprietary file formats (e.g. raw image files)
- Yes
Unlimited size per file
- No
- To use the browser-based upload function, file can’t exceed 2.5GB. However, Harvard Dataverse is willing to work with Harvard researchers who have larger files.
Unlimited total dataset size
- Yes
- 1TB per researcher. Harvard Dataverse will work with Harvard researchers who have larger datasets (>1 TB).
Data Licensing
CC0 waiver
- Recommended
- Harvard Dataverse strongly encourages use of a Creative Commons Zero (CC0) waiver for all public datasets, but dataset owners can specify other terms of use and restrict access to data.
Data Attribution and Citation Tools
Assignment of dataset DOIs
- Yes
- Harvard Dataverse assigns a DOI to each dataset and datafile within a dataverse.
- Dataset authors can identify themselves and other types of data contributors using the following types of unique IDs: ORCID, ISNI, LCNA, VIAF, GND, DAI, ResearcherID, Scopus ID.
User Access Controls
Tiered access (e.g. administrator-level, collaborator-level, curator-level)
- Yes
- Harvard Dataverse allows draft, unpublished, and published (public) datasets. For draft and unpublished datasets, a variety of tiers of access can be assigned to different registered users.
Journal-integrated, anonymous access (for peer review pre-publication)
- Yes
- The Harvard Dataverse Repository offers open access, restricted, and embargo options for all files, along with the ability to apply standard licenses and add custom terms of data access.
Optional embargo to data release following publication
- Yes
Data Access Tools
Comprehensive data and metadata search tools
- Yes
- Without logging in, users can browse a Dataverse installation and search for Dataverse collections, datasets, and files, view dataset descriptions and files for published datasets, and subset, analyze, and visualize data for published (restricted & not restricted) data files.
Data access via direct download
- Yes
Data downloading via API
- Yes
- In addition to individual file downloading, Harvard Dataverse has multiple APIs for programmatic data and metadata access, as described in the Dataverse API Guide
Built-in tools for reading proprietary file formats
- No
Integrated data analysis tools
- Yes
- Harvard Dataverse includes external tools that provide additional features that are not part of the Dataverse Software itself, such as data file previews, visualization, and curation.
Cost
Data deposition fees
- None
- Harvard Dataverse Repository is free for all researchers worldwide (up to 1 TB).
Data maintenance fees
- None
Dryad Features & Specifications
Data Size and Format
Hosting of common file formats (e.g. CSV, TSV, XLS, XLSX, DOC, PDF)
- Yes
- Prefers all data be submitted in non-proprietary, openly-documented formats that are preservation-friendly. Will accept other file types if they are "community-accepted" format. Do not accept submissions with personally identifiable information.
Hosting of proprietary file formats (e.g. raw image files)
- Yes
Unlimited size per file
- No
- No specified amount; no limit on storage space per researcher.
Unlimited total dataset size
- Yes
- 300GB/dataset
Data Licensing
CC0 waiver
- Required
- Creative Commons Zero (CC0) Any data submitted will be published under the CC0 license. Does not currently support any other license types, nor allow for restrictions on data access or use.
Data Attribution and Citation Tools
Assignment of dataset DOIs
- Yes
- Each dataset published receives a DOI for the data submission as a whole. A suffix is added to the DOI when a data file or dataset is revised to enable version control.
User Access Controls
Tiered access (e.g. administrator-level, collaborator-level, curator-level)
- No
Journal-integrated, anonymous access (for peer review pre-publication)
- Yes
- Can be shared anonymously and securely with editors and reviewers at the subset of journals that have integrated repository into their editorial workflow.
Optional embargo to data release following publication
- Yes
Data Access Tools
Comprehensive data and metadata search tools
- No
- Machine Readable metadata, primarily consists of keywords and information about the associated publication. Detailed, file-associated metadata are not records and thus not searchable. Uses the DataCite metadata schema.
Data access via direct download
- Yes
Data downloading via API
- Yes
- All datasets are free to download when published. Individual file downloading, multiple API's for programmatic data and metadata access.
Built-in tools for reading proprietary file formats
- No
Integrated data analysis tools
- No
Cost
Data deposition fees
- Yes
- $120 data publishing charge unless funded by the institution, publishers or funders. Users can download datasets free of charge once they are published.
Data maintenance fees
- None
figshare Features & Specifications
Data Size and Format
Hosting of common file formats (e.g. CSV, TSV, XLS, XLSX, DOC, PDF)
- Yes
- All file types (both compressed and non-compressed formats) are accepted. Some file types are rendered in the browser page. Files are tagged as follows: figures, datasets, media, code, paper, thesis, poster, presentation, and fileset.
Hosting of proprietary file formats (e.g. raw image files)
- Yes
Unlimited size per file
- No
- System-wide limit of 5TB per file.
Unlimited total dataset size
- No
- 20GB of private data files. Figshare+ (designed for larger datasets) offers storage in stages beginning with 100GB up to over 10TB per dataset. No limit on storage space per researcher.
Data Licensing
CC0 waiver
- Recommended
- Code and software licenses include MIT, GPL-3.0, or Apache-2.0.
- All other files: CC-BY. These licensing rules apply to all individuals uploading files directly to figshare. Institutions and publishers are allowed to mandate alternative licenses.
Data Attribution and Citation Tools
Assignment of dataset DOIs
- Yes
- figshare assigns a DOI to each individual file at the point of publication. Authors can also add an ORCID ID, so all items are pushed to ORCID. Related files can be aggregated under a master DOI encompassing a Collection. A suffix is added to a file-level DOI when a file is revised or replaced to enable version control.
User Access Controls
Tiered access (e.g. administrator-level, collaborator-level, curator-level)
- Yes
- Before the dataset is released publicly, a user can share it with a private sharing link or through a project/collaboration group.
Journal-integrated, anonymous access (for peer review pre-publication)
- Yes
- Publishers who have integrated their editorial workflow with figshare may have additional user access controls enabled to allow the journal's editors and reviewers to have anonymous and secure access to files before they are made public.
Optional embargo to data release following publication
- Yes
Data Access Tools
Comprehensive data and metadata search tools
- Yes
- Free-text search functionality is provided. Limited metadata, which consist of keywords and information about any associated publication, are recorded.
- Detailed, file-associated metadata are not recorded in the general-use figshare repository and thus are not searchable, but institutional figshare instances are allowed to develop custom metadata standards.
Data access via direct download
- Yes
Data downloading via API
- Yes
- In addition to individual file downloading, figshare has an API for programmatic data and metadata access.
Built-in tools for reading proprietary file formats
- Yes
Integrated data analysis tools
- No
Cost
Data deposition fees
- None
- Figshare+ has a one-time fee based on the size of the dataset requested.
Data maintenance fees
- None
GigaDB Features & Specifications
Data Size and Format
Hosting of common file formats (e.g. CSV, TSV, XLS, XLSX, DOC, PDF)
- Yes
Hosting of proprietary file formats (e.g. raw image files)
- No
- Only non-proprietary file types are accepted.
Unlimited size per file
- Yes
Unlimited total dataset size
- Yes
Data Licensing
CC0 waiver
- Required
- An appropriate Open-Source Initiative (OSI) or other open-source license can be applied to software files, workflows, and virtual machines.
Data Attribution and Citation Tools
Assignment of dataset DOIs
- Yes
- Each dataset will be assigned a DOI that can be used as a citation in future articles and publications. No files present at the time of publication can be removed, but a versioning system allows authors to add new files after publication if needed. Detailed information about the data should be submitted by the authors in ISA-Tab.
User Access Controls
Tiered access (e.g. administrator-level, collaborator-level, curator-level)
- No
Journal-integrated, anonymous access (for peer review pre-publication)
- Yes
- Through the GigaDB staging server, the journal's editors and reviewers have anonymous and secure access to files before they are made public, and authors can submit revised files during the peer-review process.
Optional embargo to data release following publication
- Yes
Data Access Tools
Comprehensive data and metadata search tools
- No
- Free-text search functionality is provided. Detailed, file-associated metadata are not recorded and thus are not searchable.
Data access via direct download
- Yes
- Datasets may be downloaded via FTP or via a browser using GigaDB's Aspera server software. For larger datasets, GigaScience will copy data to a hard drive and ship it to a user (at the user's expense).
Data downloading via API
- No
Built-in tools for reading proprietary file formats
- No
Integrated data analysis tools
- Yes
- Author-provided tools are hosted in GigaDB or on the GigaGalaxy server and linked to from the associated paper's GigaScience landing page.
Cost
Data deposition fees
- None
- Data deposition costs for up to 1 TB of data are included in the standard article publication charge. All data provided by GigaDB is free to download and use.
Data maintenance fees
- None
IEEE DataPort Features & Specifications
Data Size and Format
Hosting of common file formats (e.g. CSV, TSV, XLS, XLSX, DOC, PDF)
- Yes
- The following formats are currently supported: ZIP, GZ, gzip, CSV, JSON, TXT, SQL, XML, TSV, EBS, Avro, ORC, Parquet, HDF5, 7z, TBZ2, ISO, tar, BZ2, Z, XLS, XLSX, graph, properties, offsets, FLAC, OGG, WAV, AAC, MP3, GIF, JPG, JPEG, PNG, AVI, MOV, MP4, MPG, M4V, YAML, DAT, MAT, fig.
Hosting of proprietary file formats (e.g. raw image files)
- Yes
Unlimited size per file
- No
- No individual file size limit. For large datasets, upload a series of files that are 100 GB or less. For datasets with a large number of files (>100), compress your upload(s) using the ZIP and/or GZIP format.
Unlimited total dataset size
- No
- Up to 2TB of storage or 10 TB for Institutional Subscribers for each dataset.
Data Licensing
CC0 waiver
- CC-BY
- Datasets on IEEE DataPort are made available under Creative Commons Attribution (CC-BY) licenses which require attribution.
Data Attribution and Citation Tools
Assignment of dataset DOIs
- Yes
- Datasets on IEEE DataPort are made available under CC-BY licenses which require attribution. Any use requires citation. IEEE DataPort includes a Cite button on each dataset page so a user can easily obtain the proper citation for the dataset. The citation provided by using the Cite button is provided in multiple formats to facilitate easy attribution.
User Access Controls
Tiered access (e.g. administrator-level, collaborator-level, curator-level)
- No
- IEEE DataPort is a self-monitoring system with feedback mechanisms so users can provide comments on datasets.
Journal-integrated, anonymous access (for peer review pre-publication)
- No
Optional embargo to data release following publication
- No
Data Access Tools
Comprehensive data and metadata search tools
- No
- To search, access, and analyze datasets on IEEE DataPort, you first need to create a free IEEE account or login with your existing account. After logging in you can search datasets by entering keywords in the search bar or by browsing the dataset categories. Once a desired dataset is located you can access it by simply clicking on the dataset.
Data access via direct download
- Yes
- Users need to subscribe to access and/or download Standard datasets on IEEE DataPort. Open Access datasets are available to all registered users of IEEE DataPort.
Data downloading via API
- Yes
Built-in tools for reading proprietary file formats
- Yes
- IEEE DataPort is data agnostic and will allow any format of dataset to be submitted for storage on IEEE DataPort. The provision of metadata, tools and/or supporting documentation allow the user to understand how each specific dataset can be analyzed.
Integrated data analysis tools
- Yes
- You can then view and analyze the dataset. If you do not have sufficient storage and computing capacity on your local system to perform the analysis, IEEE currently provides access to the dataset in the Cloud to facilitate the analysis. Once your analysis is complete, you can upload the analysis by clicking the “submit an analysis” button directly below the dataset image.
Cost
Data deposition fees
- Membership
- An individual subscription allows you to view, download and/or access in the cloud all datasets, store your own research data at no cost, and access data management features. Individual subscriptions are free for all IEEE Society Members or $40/month.
Data maintenance fees
- Membership
Mendeley Data Features & Specifications
Data Size and Format
Hosting of common file formats (e.g. CSV, TSV, XLS, XLSX, DOC, PDF)
- Yes
Hosting of proprietary file formats (e.g. raw image files)
- Yes
Unlimited size per file
- No
- 10GB per dataset
Unlimited total dataset size
- No
- Mendeley Data datasets for personal accounts have a maximum limit of 10 GB per dataset. However, if your Institution subscribes to Mendeley Data you will have the ability to create datasets up to a maximum size of 100GB. The maximum size will depend on the storage agreement that your institution has.
Data Licensing
CC0 waiver
- Recommended
- Users can choose from a range of 16 licenses that can be applied to data, with the default being Creative Commons Zero (CC0).
Data Attribution and Citation Tools
Assignment of dataset DOIs
- Yes
- Mendeley Data reserves a DOI when the dataset is created and mints it when the dataset is published.
- Mendeley Data provides PIDs for individual files and folders within a dataset.
User Access Controls
Tiered access (e.g. administrator-level, collaborator-level, curator-level)
- Yes
- Each draft dataset has a share link which you can copy to send to collaborators; they’ll be able to access the dataset metadata and files prior to publishing.
Journal-integrated, anonymous access (for peer review pre-publication)
- Yes
Optional embargo to data release following publication
- Yes
- When publishing a dataset, a user may choose to defer the date at which the data becomes available (for example, so that it is available at the same time as an associated article).
Data Access Tools
Comprehensive data and metadata search tools
- Yes
- You can search for datasets by keyword, within dataset metadata and data files. You can perform an advanced search using field codes to target one or more specific fields and / or boolean operators.
Data access via direct download
- Yes
- If the dataset owner has decided to allow the download of datasets, this can be done freely and only the download count is tracked.
- You can download all the files within the dataset using the “Download All” button in a Published dataset, which will give you the file size before you start the download and create a zip file with the Dataset name and version. You can see the same structure of the dataset including all the subfolders, within the zip file.
Data downloading via API
- Yes
Built-in tools for reading proprietary file formats
- No
Integrated data analysis tools
- No
Cost
Data deposition fees
- None
- The communal repository is available free of charge for individual researchers who want to publish relatively small datasets (up to 10GB each).
Data maintenance fees
- None
Open Science Framework (OSF) Features & Specifications
Data Size and Format
Hosting of common file formats (e.g. CSV, TSV, XLS, XLSX, DOC, PDF)
- Yes
- Any type of file can be uploaded. Most files will render directly in the File Viewer. For example, if the file is an image, you can zoom in and out on details.
Hosting of proprietary file formats (e.g. raw image files)
- Yes
Unlimited size per file
- No
- 5GB/file upload limit for native OSF Storage. There is no limit imposed by OSF for the amount of storage used across add-ons connected to a given project.
Unlimited total dataset size
- Yes
- 50 GB
Data Licensing
CC0 waiver
- Yes
- Users can choose from a long list of licenses. Users can also define a license in a .txt file and uploads to the project.
Data Attribution and Citation Tools
Assignment of dataset DOIs
- Yes
- OSF uses Globally Unique Identifiers (GUIDs) on all objects (users, files, projects, components, registrations, and preprints) across the platform, which are citable in scholarly communication. OSF also supports registration of DOIs for projects, components, and research registrations with DataCite, and for preprints with Crossref. OSF collects ORCID iDs for users and contributors, and provides those with metadata sent for DOI minting, as well as ROR identifiers when contributor affiliations are known.
- OSF does not currently support DOI versioning.
User Access Controls
Tiered access (e.g. administrator-level, collaborator-level, curator-level)
- Yes
- OSF supports request access and private sharing settings, as well as view only link with ability to anonymize contributor list.
- Contributors are a group of collaborators within a project, component, registration, or preprint. Projects and components have individual contributor lists and permissions levels, so you can control who can access and modify your work.
Journal-integrated, anonymous access (for peer review pre-publication)
- Yes
- You can create a view-only link to share projects so those who have the link can view—but not edit—the project, and also the anonymize contributor list (e.g., for peer review).
Optional embargo to data release following publication
- No
Data Access Tools
Comprehensive data and metadata search tools
- Yes
- Free Text Search functionality provided. The OSF Search interface offers a few options for filtering search results. Tags are automatically indexed by search for public content.
Data access via direct download
- Yes
- Access to view and download public content on OSF is free and does not require an account. You can download individual or multiple Quick Files to save and view them on your computer.
Data downloading via API
- Yes
- Files stored on OSF can also be downloaded locally through the API.
Built-in tools for reading proprietary file formats
- No
Integrated data analysis tools
- No
Cost
Data deposition fees
- None
- OSF is free to use by research producers and consumers. Signing up for an account on OSF is quick and easy, by providing a name, email, and password, or by using ORCID or institutional credentials (including Harvard Key).
Data maintenance fees
- None
Science Data Bank (ScienceDB) Features & Specifications
Data Size and Format
Hosting of common file formats (e.g. CSV, TSV, XLS, XLSX, DOC, PDF)
- Yes
- They prefer non-proprietary file formats, which can be found in the Science Data Bank Preferred File Format table.
Hosting of proprietary file formats (e.g. raw image files)
- Not preferred
Unlimited size per file
- Yes
Unlimited total dataset size
- Yes
Data Licensing
CC0 waiver
- Yes
- CC0 is the default license assigned to datasets.
- ScienceDB provides the following licensing options: CC0, CC-BY 4.0, CC BY-SA 4.0, CC BY-NC 4.0, CC BY-NC-SA 4.0, CC BY-ND 4.0, CC BY-NC-ND 4.0, and 3 licenses for database: PDDL, ODC-By, ODbL, as well as 12 software license agreements: MIT, Apache-2.0, AGPL-3.0, LGPL-2.1, GPL-2.0, GPL-3.0, BSD-2-Clause, BSD-3-Clause, MPL-2.0, BSL-1.0, EPL-2.0 and The Unlicense. For more information, see the Science Data Bank FAQ webpage.
Data Attribution and Citation Tools
Assignment of dataset DOIs
- Yes
- Once a submission is published, ScienceDB assigns a DOI to each dataset. A Commons Science and Technology Resource (CSTR) is also assigned to accepted datasets. Data depositors can select their preferred data citation format.
User Access Controls
Tiered access (e.g. administrator-level, collaborator-level, curator-level)
- No
- At the time of data submission, users may select to an open access or embargo option. Files can be restricted to require users to request access through a Data Access Application.
Journal-integrated, anonymous access (for peer review pre-publication)
- Yes
Optional embargo to data release following publication
- Yes
Data Access Tools
Comprehensive data and metadata search tools
- Yes
Data access via direct download
- Yes
Data downloading via API
- Yes
- OPEN-API allows users to access datasets programmatically. All metadata is harvested via OAI-PMH.
Built-in tools for reading proprietary file formats
- No
Integrated data analysis tools
- No
Cost
Data deposition fees
- None
- Currently, submitting data to ScienceDB is free. However, theScience Data Bank FAQ webpage states that they reserve the right to charge for submission, review, or storage in the future.
Data maintenance fees
- None
Synapse Features & Specifications
Data Size and Format
Hosting of common file formats (e.g. CSV, TSV, XLS, XLSX, DOC, PDF)
- Yes
Hosting of proprietary file formats (e.g. raw image files)
- Yes
Unlimited size per file
- Yes
Unlimited total dataset size
- Yes
Data Licensing
CC0 waiver
- Unknown
- Conditions for use are put in place to define/restrict how users who have permission to download data may use it.
- Conditions for use may include IRB approval or other restrictions that you define as the data contributor.
- You are responsible for determining if the data you would like to contribute is controlled data and therefore requires conditions for use.
- Conditions for use can be set at the project, folder, file and table level.
Data Attribution and Citation Tools
Assignment of dataset DOIs
- Yes
- Synapse items receive a unique identifier (SynID). Items that receive a SynID are files, folders, projects, tables, views, wikis, links, and Docker repositories. Each file also receives a MD5 checksum. DOIs are available in Synapse for projects, files, folders, tables, and views.
User Access Controls
Tiered access (e.g. administrator-level, collaborator-level, curator-level)
- Yes
- There are a number of Synapse user access controls for public and private projects, and sharing settings can be managed at the project, folder, file, and table level. Data containing sensitive information (i.e., data with a de-identification risk) can be restricted to specific users; users wanting access to controlled data can request individual access. Project administrators can add and manage permissions for individual team members on private projects. Public projects can either be fully public or restricted to registered Synapse Users.
Journal-integrated, anonymous access (for peer review pre-publication)
- Yes
Optional embargo to data release following publication
- No
Data Access Tools
Comprehensive data and metadata search tools
- No
Data access via direct download
- Yes
- Users are required to have a Synapse account and become a certified user in order to upload data. Data can be uploaded and downloaded via a web-based user interface or programmatically using Python, R, or the command line.
Data downloading via API
- Yes
Built-in tools for reading proprietary file formats
- No
Integrated data analysis tools
- No
Cost
Data deposition fees
- None
- Intended for individual researchers wanting to share small datasets (<100GB) for publication (including creating DOIs) and scientific, educational, and research collaborations.
Data maintenance fees
- None
Vivli Features & Specifications
Data Size and Format
Hosting of common file formats (e.g. CSV, TSV, XLS, XLSX, DOC, PDF)
- Yes
- Data sets are not required to be standardized; however, we highly recommend that data sets be made available in CDISC SDTM (Standard Data Tabulation Model) format to support the most efficient data aggregation, re-use, and sharing. In the future, Vivli will explore the use of Common Data Elements within specific clinical domains.
Hosting of proprietary file formats (e.g. raw image files)
- Yes
Unlimited size per file
- No
- Vivli data contributors can share files up to 500 MB. Larger sizes of up to 100T can be accommodated. If your file is larger than 1T, please email Vivli Support.
Unlimited total dataset size
- No
- There is no limit per researcher, and each data contribution is reviewed by Vivli.
Data Licensing
CC0 waiver
- Yes
- All data contributors must sign and conform to the Data Contributor Agreement (available upon request), which includes language about intellectual property.
Data Attribution and Citation Tools
Assignment of dataset DOIs
- Yes
- All clinical research that is available for search and request on the Vivli platform is assigned a DataCite Digital Object Identifier (DOI) at the time the metadata for the clinical research data appears in the Vivli search and is available for request.
- The clinical research dataset is assigned a main DOI with a parent-child data object reference for all data and documents associated with a study’s data package to support data discovery.
User Access Controls
Tiered access (e.g. administrator-level, collaborator-level, curator-level)
- Yes
- Datasets contributed to Vivli may be made available via various levels of access through download after signing of a Data Use Agreement.
Journal-integrated, anonymous access (for peer review pre-publication)
- Yes
Optional embargo to data release following publication
- Yes
Data Access Tools
Comprehensive data and metadata search tools
- Yes
- The Vivli platform allows users to search through listed studies using three search methods, including a Keyword Search, PICO Search, and Quick Study Look-up.
Data access via direct download
- Yes
- To request data, a researcher or team must first create an account on Vivli and submit a research proposal.
Data downloading via API
- No
Built-in tools for reading proprietary file formats
- Yes
- Yes, through Vivli’s secure research environment.
Integrated data analysis tools
- Yes
- Use robust analytical tools to combine and analyze multiple datasets. Vivli’s secure research environment is a virtual work-space within the Vivli platform where researchers who have been provided access to data, will have remote desktop access to conduct their analysis. Researchers will have access to SAS, STATA, R, Python, Jupyter, and the Microsoft Office suite to enable analysis of shared data sets. If desired, additional analytical tools, data and scripts may be included in a research team’s secure research environment.
Cost
Data deposition fees
- Membership
- Access to metadata and data hosted by Vivli is free and accessible to all, subject to meeting a data contributor’s data sharing policies.
- If your academic institution is a member of Vivli there is no cost to deposit data in Vivli’s platform starting in 2023.
- If your academic institution is not a member, there is a one-time cost to use Vivli’s managed access process for clinical research data.
- Service fee for clinical trial datasets (<500GB): $4,000
- Larger clinical trial datasets (>500GB): $10,000
- Optional anonymization services provided by Privacy Analytics: $10,000 per dataset
Data maintenance fees
- Membership
Zenodo Features & Specifications
Data Size and Format
Hosting of common file formats (e.g. CSV, TSV, XLS, XLSX, DOC, PDF)
- Yes
- All file types are accepted. Files are categorized as: publications, posters, presentations, datasets, images, software, videos/audio, and interactive materials. Zenodo also integrates with GitHub to deposit GitHub repositories for sharing and long-term preservation.
Hosting of proprietary file formats (e.g. raw image files)
- Yes
Unlimited size per file
- No
- Total files size limit per record is 50GB. Higher quotas can be requested and granted on a case-by-case basis
Unlimited total dataset size
- No
- Currently accept up to 50GB per dataset (you can have multiple datasets). There is no size limit on communities. Zenodo also encourages researchers to reach out to discuss use cases with larger dataset sizes.
Data Licensing
CC0 waiver
- Yes
- Users can choose from a long list of licenses, with the default being Creative Commons Zero (CC0). Users must specify a license for all publicly available files.
Data Attribution and Citation Tools
Assignment of dataset DOIs
- Yes
- Zenodo assigns all publicly available uploads a Digital Object Identifier (DOI) to make the upload easily and uniquely citable. Zenodo further supports harvesting of all content via the OAI-PMH protocol. Also allows the user to enter a previously assigned DOI.
User Access Controls
Tiered access (e.g. administrator-level, collaborator-level, curator-level)
- Yes
Journal-integrated, anonymous access (for peer review pre-publication)
- Yes
Optional embargo to data release following publication
- Yes
- Users can choose to deposit files under open, embargoed, restricted, or closed access. For embargoed files, the user can choose the length of the embargo period, and the content will become publicly available automatically at the end of the embargo period. Users may also deposit restricted files and grant access to specific individuals.
Data Access Tools
Comprehensive data and metadata search tools
- No
- Free-text search functionality is provided. Machine-readable metadata are also recorded, according to the Invenio Digital Library Framework. Zenodo communicates with existing services, such as Mendeley, ORCID, Crossref, and OpenAIRE for pre-filling metadata.
Data access via direct download
- Yes
Data downloading via API
- Yes
- In addition to individual file downloading, Zenodo has an OAI-PMH API for programmatic data and metadata access, as described in the Zenodo API documentation
Built-in tools for reading proprietary file formats
- No
Integrated data analysis tools
- No
Cost
Data deposition fees
- None
Data maintenance fees
- None