
File Organization
One of the most essential aspects of data management is organizing your data. This includes several elements, including thinking through names, structures, and relationships.
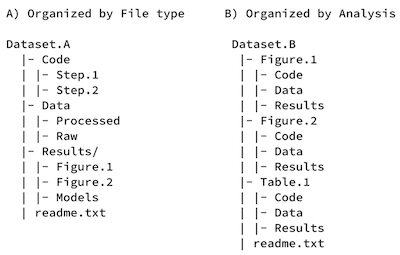
Researchers are advised to structure their folders (whether paper or electronic in form) to correspond to how the records were generated and to complement proposed or existing workflows.
- Filing structures enable research processes to be more transparent, make it easier for investigators to determine where files should be saved, and ultimately make retrieval and archiving more efficient
- Established file plans demonstrate consistency and continuity in recordkeeping
- Before you even start collecting or working with data, you should decide how you will structure and name files and folders to allow for standardized data collecting and analysis by many team members

RDM Seminar Recorded Summer 2020
Watch the following video to learn more about organizing your files